On Functions That Implement Interfaces and the Elegance of Go
One of the reasons that I enjoy programming in Go so much is that its design is so elegant. Let me try to explain what I mean by that.
Many years ago, I was studying Game Design with a group of friends. During that time, I came across a book that I find myself quoting from in many situations to this day, The Art of Game Design, by Jesse Schell. In one of my favorite parts of this book, the author discusses the topic of elegance:
We call simple systems that perform robustly in complex situations elegant. Elegance is one of the most desirable qualities in any game because it means you have a game that is easy to learn and understand but is full of interesting emergent complexity. 1
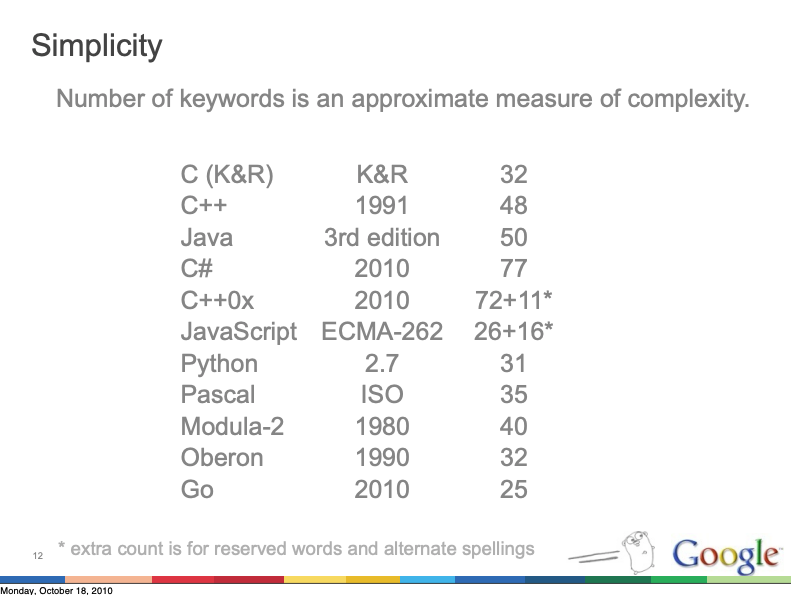
If you’ve ever written in Go, you probably see how this statement projects very nicely into describing it. Go is a notoriously simple language as shown by this slide presented in a 2010 Rob Pike talk named The Expressiveness of Go:
Despite (or because of) its simplicity, Go was chosen to build very robust and complex distributed systems (such as Kubernetes, Docker, Terraform, or CockroachDB).
But what is elegance? Can we capture it and rate it, or is it some intangible aesthetic quality that is just evident from the design of a system? Thankfully, Jesse Schell discusses this further:
You can easily rate the elegance of a given game element by counting the number of purposes it has. For example, the dots in Pac Man serve the following purposes:
- They give the player a short-term goal: “Eat all the dots close to me.”
- They give the player a long-term goal: “Clear all the dots from the board.”
- They slow the player down slightly when eating them creating good triangularity (safer to go down a corridor with no dots, riskier to go down the one with dots)
- They give the player points, which are a measure of success.
- They give the player points, which can earn an extra life. 2
Go Types and Methods
One of the great examples of elegance in Go is the way methods and types work together. In object-oriented languages such as Java, methods (functions) are coupled to types. They are, as the famous “Married with Children” theme song goes, “You can’t have one without the other”. In Go, methods, and types are said to be “Orthogonal”. What is orthogonality? “The Pragmatic Programmer”, by Andy Hunt and Dave Thomas explains:
"Orthogonality" is a term borrowed from geometry. Two lines are orthogonal if they meet at right angles, such as the axes on a graph. [..]
In computing, the term has come to signify a kind of independence or decoupling. Two or more things are orthogonal if changes in one do not affect any of the others. In a well-designed system, the database code will be orthogonal to the user interface: you can change the interface without affecting the database, and swap databases. 3
Let’s demonstrate this point. Consider this example:
package main
import (
"fmt"
)
type Person struct {
name string
}
func (p Person) Greet() {
fmt.Println("hello, ", p.name)
}
func main() {
p := Person{name: "rotemtam"}
Person.Greet(p) // calling the method directly
p.Greet() // the same, calling it "on" the receiver
}
As we mentioned, in Go, types and methods are orthogonal (decoupled) to one another: methods are just
functions that receive the type as their first parameter. In the example above, we first
defined a type Person that has a method receiver Greet. We demonstrated that we can
invoke this function via Person.Greet(p) where its first parameter is a Person,
or via the “classic” way that is similar to object-oriented languages p.Greet().
Consider the following:
package main
import (
"fmt"
)
type X struct {
}
func (*X) Invoke() {
fmt.Println("method called")
}
func main() {
var x *X
x.Invoke()
// Output: method called
}
Here we see another demonstration of the decoupling of types and methods. Because the
method Invoke is just a function that receives a pointer to X as its first argument,
we can invoke it on a nil pointer to X. In languages where types and methods are coupled
(e.g. Java) this would result in a null-pointer exception.
Orthogonality in Action
Recently, I was working a component that is part of the Atlas Project that we’re building in Ariga that gave me a great demonstration of these ideas. Specifically, I was working on a method that needs to unmarshal a document into a target struct, but the syntax of the document can vary (it can be supplied in a dialect of HCL, but other syntaxes such as JSON and YAML will be available in the future).
The interface for each syntax implementations is:
type Unmarshaler interface {
UnmarshalSpec([]byte, interface{}) error
}
And the method I was working on had the signature of:
func UnmarshalSpec(data []byte, unmarshaler schemaspec.Unmarshaler, v interface{}) error
What I was trying to find out was if there’s a neat way to pass a function (instead of a full-blown type) to my method without replacing the Unmarshaler interface with an alias to a function signature. I had remembered seeing something like that in the standard library, but couldn’t recall where. Luckily, my good friend and partner in crime, Ariel, is a very serious gopher, and he can cite large parts of the standard library from memory if you wake him up in the middle of the night.
So, can it be done? Recall a few characteristics of Go:
- Methods can be implemented for any type
- Functions can be the “underlying type” of other types.
- Interfaces represent abstraction.
Assume we have a function, that we want to pass to UnmarshalSpec as an implementation of
the schemaspec.Unmarshaler interface:
func unmarshal(data []byte, v interface{}) error {
// ...
}
We can define a new type:
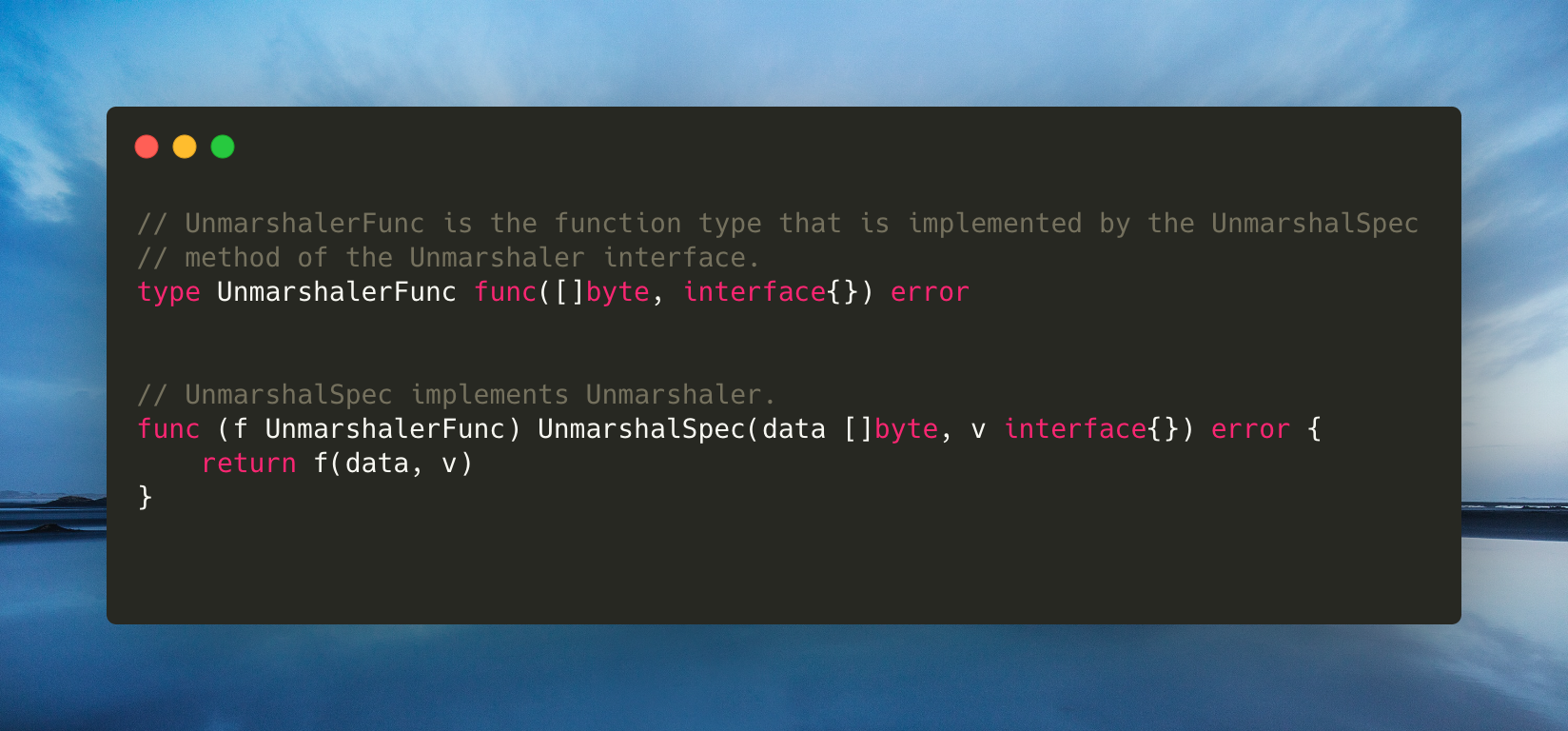
type UnmarshalerFunc func([]byte, interface{}) error
And this new type can implement schemaspec.Unmarshaler by invoking itself!
// UnmarshalSpec implements Unmarshaler.
func (f UnmarshalerFunc) UnmarshalSpec(data []byte, v interface{}) error {
return f(data, v)
}
Next, we convert our existing function to the new UnmarshalerFunc type:
var Unmarshal = UnmarshalerFunc(unmarshal)
And, voila! Unmarshal can now be passed to our function as a schemaspc.Unmarshaler.
If this looks familiar, it should be because this is exactly what is done in the standard
library’s net/http package. As explained in this blog post,
the net/http package provides a function named HandlerFunc that can be used to convert a single function to a type that
implements the http.Handler interface.
Wrapping Up
I think that the way this pattern, which is sometimes called “Functional Interfaces” in other languages, is implemented in Go is a perfect example of the concept of elegance: simple systems that perform robustly. Just by using three simple, orthogonal concepts: methods, types and interfaces, so much is possible. Aside from the joy of using something that is well designed, there’s a good lesson and inspiration here to anyone who wants to build great software.
1 The Art of Game Design, p.187 Jesse Schelle. Morgan Kaufmann Publishers
2 Ibid.
3 Thomas, David; Hunt, Andrew. The Pragmatic Programmer . Pearson Education. Kindle Edition.