The statically-typed organization, part I
As your software-organization grows in: headcount, service count, programming language count it becomes increasingly harder to coordinate work.
Let me try to illustrate this. Let’s say you are working on a new workflow that requires you to send push notifications to some clients of your mobile app. Another team is maintaining the OutboundMessagingService , a microservice written in Java that deals with all the messy details of sending push notifications to users on mobile platforms such as iOS and Android. You, being the solid software engineer that you are, want to re-use their good work, what do you do?
If you’re lucky, the team that published the service maintains a client library in the language you’re working in. All you have to do is import their library code, look at the method definitions and invoke them, done.
You check with them, and they are indeed maintaining a client library for their projects, but unfortunately for you, they coded it in Java, the main language their team is working in. No plans to publish a Ruby client, which you really need for that Rails app you’re working on. They did go through the trouble of documenting the API, though. One of the engineers on the team sends you a link to the company Wiki page with the documentation and you start building your client.
Half-way through coding your Ruby client, you do a small test-run and try to make an actual call to the service, as the docs specify:
{
"userId": "9C96A22B-A4F1-4965-BE4C-64C51A1CF519",
"message": "Hello, world!"
}
No matter how you modify your request URL, re-create your authentication token, you keep getting this cryptic response with a 400 HTTP status code:
{
"error": "Bad Request"
}
You check with the one of the engineers on the team. Together you start going through the OutboundMessagingService logs until you locate your request and find the exception. “Oh!”, says the engineer you’re working with, “we did replace the message field with a payload object a few months ago. We updated the Java client, but I guess no one remembered to update the docs on the Wiki, sorry.”
You update your client code to use the correct input object, and lo and behold, a push notification pops up on your iPhone screen.
In this case you were lucky enough to hit a team that was still maintaining the service, and they were responsive enough to debug the issue with you. If that weren’t the case, you would probably would have had to dig in to their service source code to try to figure out what’s what. In one extreme case that happened to me I had to install wireshark on a server machine to snoop real traffic to figure out how to implement a client to one of our services at work. I had the source code in a language I didn’t read well to guide me, imagine doing this against a compiled, black-box service!
In a monolithic (single process) system, or even in a monoglot (single language) system, contracts are somewhat defined and enforced by function signatures; servers and clients can share classes (as long as they are running the same version of the code) and know exactly what the inputs and outputs are for a given procedure.
In a microservice-oriented, polyglot system, this can quickly become untenable, or at the very least expensive to manage. If schemas aren’t formally defined, synchronizing field names, enum options, etc. is dependent on informal communication between engineers, which will most probably not be documented and definitely not be version controlled.
As your company grows, scenarios like we illustrated above become increasingly more common; engineers go through these painstaking processes because your company is slowly losing the ability to coordinate and enforce contracts/interfaces between different services. As reusing another team’s good work becomes harder and harder, silos develop and each engineering group builds their own version of core competencies. This is bad news for a software engineering organization.
Statically-typed languages
The approach I want present in this article to remedy this issue, is one that I like to call “the statically typed organization”, because it takes the things I value about statically typed programming languages and applies them to the organizational level.
First, let’s start with some definitions, just so we’re on the same page. When I say a statically-typed language, I mean a language (and compiler/interpreter) in which the types of values are known before runtime and checked at compile time. By contrast, Python, a dynamically-typed language (and interpreter) doesn’t care much about types until a function is actually invoked:
def add(a, b):
return a + b
# this works
add("a", "b") # returns string "ab"
# and this also works
add(1, 2) # returns int 3
When we declare our add function in Python, the language doesn’t care much which types our input variables are going to be of, as long as they implement the magic function __add__. This has the cool quality of implicitly introducing interfaces (called duck-typing in this case) into the language, we can pass anything which is add-able to this function and it will just work.
The downside is, of course, that this can have unintended or unpredicted consequences. A function intended to add integers will accidentally receive strings as arguments, and the program will start running just fine, leading to hard to predict exceptions at runtime. Often, programmers writing library code in dynamic languages will defend themselves against these kinds of cases by asserting types at runtime. In a way similar to:
def add(a, b):
assert type(a) == type(b) == int, 'a and b must be integers'
return a + b
add(1, "b") # fails with : AssertionError: a and b must be integers
This pattern will help us gain some more certainty about the execution of this function, and will signal to developers using our function that they provided bad input, but can be avoided altogether by using a statically typed language.
In a statically-typed language, the types of variables are known before runtime and checked at compile time. This, of course, doesn’t happen magically, as a rule of thumb, in statically typed languages code will be more verbose: we will explicitly define our function signatures. But with this verbosity, comes the upside of type safety, for example in Go:
func add(a, b int) int {
return a + b
}
add("a", "b") // will not compile: cannot use "a" (type string) as type int in argument to add
add(1, 2) // will compile and return 3
By “type-safety” I mean that in the above example, the Go compiler will prevent us from making type errors, passing the wrong kind of type to a function.
Another awesome feature of this is that statically-typed code can be statically analyzed as you type it, and therefore IDEs are extermely adept at offering suggestions of possible valid things you could type:
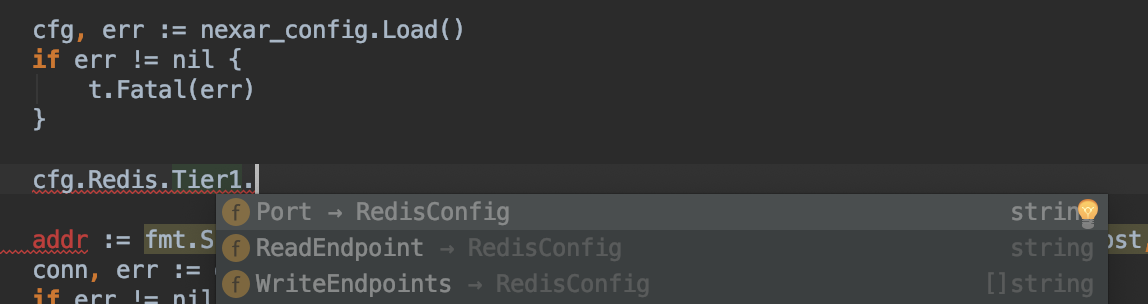
(our IDE knows thatcfg.Redis.Tier1 is of typeRedisConfig and therefore has fieldsPort, ReadEndpoint and []WriteEndpoints)
As well as warn us when we type something that will not compile:
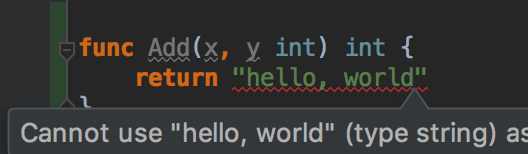
(our IDE knows thatAdd()is supposed to return anint, and thus warns us the our code won’t compile)
With the definitions all set, I now give you:
The statically-typed organization
In a statically-typed organization:
- No message crosses process boundaries which is not backed by a predefined, shared schema.
- Message schema is defined in code, in a language agnostic format
- Language specific code is generated programmatically from the schema definition and is available to developers as they code
- Language specific code must be able to serialize and deserialize messages into a wire-format that is common between all language implementation
- Message schema is version-controlled in an organization-wide shared repository
- Schemas must be forward and backward compatible, i.e. old code must be able to read without error messages serialized with new code and vice versa.
The benefits of working in a statically typed organization (STO, henceforth):
- Easier to code. Developers are relieved of the communication and mental overhead of trying to figure out the schema of the messages they should pass around. Guesswork of finding out what a service might return (field name, field types) is eliminated, resulting in much higher development velocity and less potato-potatoe bugs.
- Cross-team type safety. Developers working in statically-typed languages get full code-completion and type checking for all of the organization’s APIs, as they type; those working in dynamic languages at the very least get runtime exceptions very early in their work-cycle. Faster feedback contributes further to development velocity.
- Easier to bootstrap a project. Interfaces between services are defined before implementation, meaning a client does not need to wait for the server to be implemented to start working. Mocks of the server can be generated programmatically to bootstrap work on a feature. Furthermore, the client code in its final form is generated from the get go, resulting in even higher development velocity.
- Utilization of existing quality control mechanisms. If schemas are version controlled, in a shared repository, changes to the schema are subject to normal code-review and continuous integration processes contributing to enforcement of organizational standards around naming and general code quality.
- More efficient wire-formats. Because serializers and deserializers are created programmatically and are common across the organization they can be optimized once per language. By using specialized encodings, savings in space/running time can be made that an individual developer working on implementing a product feature will rarely have the time and resources to make, contributing to more efficient resource utilization (CPU, memory, network bandwidth).
The costs of working in an STO:
- More process. Changing the signature of a publicly exposed function or adding a field to a message is slower: a developer needs to make a PR to the schema repository as well the application repository.
- Constant regeneration of scheme classes. Every change in the schema requires a re-build of the generated classes.
- Working around generated code. Generated code can not be edited (generally shouldn’t be checked-in to source control). Therefore classes will generally be solely data-containers, adding business logic to the entity classes will require somehow extending them (via inheritance/embedding). Another pain point is that typically machine-generated code is ugly , hard to read and any bugs found in it cannot be directly fixed - the code generator must be patched instead.
- Developer on boarding overhead. New staff must be trained to understand and use these workflows.
In general, we can say that the same kind of trade-off that is made by a single developer who chooses to work in a statically typed language, is made by an organization that chooses to be statically-typed: verbosity for safety, rigidity for velocity.
When contemplating becoming an STO, we should also consider the cost of not having formally defined, programmatically enforced schemas which is:
- More bugs. A high probability of introducing schema-related bugs which is increasing with the size of the organization.
- Wasted engineering time on local optimizations. Experienced engineers working in an unsafe environment will go to great lengths to protect their programs from such errors by implementing ad-hoc type-checking at runtime and by developing large test-suites which try to simulate any such errors that they are able to conceive. This of course is a wasteful, local optimization, which will be repeated over and over unless some more infrastructural approach is taken.
On the next episode of “the statically-typed organization”:
This concludes the first part of this series, in the next installments we will discuss:
- Message serialization and deserialization considerations in an STO
- Protocol Buffers as a technology to implement STOs
- Additional guidelines and lessons learned around STOs