Serverless Applications. continuous delivery with AWS Lambda and API Gateway — Part 1, Unit tests
At ironSource’s Data Solutions dept., we work on ironSource atom, a data flow management platform to help our clients easily deal with massive amounts of data. We help companies create custom big-data pipelines into which they can stream data which will be safely collected, transformed and loaded into one of many big-data target types such as Amazon Redshift.
We recently decided to build an internal microservice to help us manage the configuration of our clients’ pipelines. This service would be extremely mission critical and would therefore have to be highly available. We were comfortable writing in Node.js but we really didn’t want the hassle of managing another Node app, babysitting the machines, running security updates and waking up at 2AM when our NOC knocks. We read about serverless apps, and were excited to try building a microservice using AWS API Gateway and Lambda.
The plan
Our app would be built like this:
- API Gateway would be in charge of accepting HTTP requests, managing authentication and caching
- Each endpoint in the gateway would map to a Lambda Function (i.e GET /streams would map to a API_getStreams function)
- Data will be persisted in DynamoDB tables
 for the awesome 3d image](https://cdn-images-1.medium.com/max/800/1*fY_FBhZMKSb-7dC48R-DPQ.png) Thanks to cloudcraft.co for the awesome 3d image
Thanks to cloudcraft.co for the awesome 3d image
Building serverless applications is really great. The benefits are abundant: having no responsibility for managing any servers, paying only for what you use, getting very high availability out of the box, not having to deal with rolling deployments, and much more. Serverless apps deliver on one of the basic tenents of cloud computing: elasticity. First came VMs to provide flexibility on top of servers, then came Docker containers and now (supposedly) the third wave of Cloud Computing is here — with serverless architecture.
Tough Realities of Developing a Serverless Service
While using API Gateway and Lambda is great and takes a lot of hassle away from managing the service when it’s already been deployed, achieving continuous integration and deployment isn’t trivial. A typical manual deployment would include:
- Writing the code locally.
- Creating a new Lambda function in the AWS Console UI.
- Copy and pasting the code, deploying.
- Testing the function with various inputs from the UI.
- Creating a resource (=route) in the API Gateway via the UI.
- Connecting the resource to the Lambda function.
- Configuring input parameters, error handling, security and more via the API Gateway UI.
- Integration testing by calling the API Gateway directly using Postman.
As you can see, this process is very costly (and boring). Generally, our philosophy in ironSource atom is this:

Naturally, we were inclined to develop an automated way of doing all this grunt work. In this article we will describe the configuration we use to go from code to a running service in production in a way that doesn’t suck.
(Sneak-peek: to see a demo project with all the things we’re going to cover in this series, visit this github repo)
Unit Tests
The first step to creating a continuously deployable service is to write unit tests. If you want to deploy many times a day, you have to be sure you didn’t break anything! While we had quite a lot of experience writing unit tests in node we weren’t sure how to unit test Lambda. Lambda functions expect the developer to expose a method which behaves sort of like this:
module.exports = {
default: function(e, ctx) {
// do stuff
if ( err ) {
context.fail(err)
} else {
context.succeed('yay!')
}
}
}
Your function will be called with an input parameter e and a Lambda context object ctx. Lambda expects you to call ctx.succeed( .. ) when you’re done running or to call ctx.fail( .. ) if you need to throw an error_._ In order to work with this expected syntax we created a tiny Lambda context mock object which looks like this:
const sinon = require('sinon');
module.exports = function() {
let _this = this;
this.succeed = sinon.stub(),
this.fail = sinon.stub(),
this.reset = function() {
_this.succeed.reset();
_this.fail.reset();
};
};
This way we can easily write unit tests to test our functions using Mocha.js. Assume we wanted to test this Lambda function:
'use strict';
module.exports = function doSomething(e, ctx, cb) {
if (e.someParam > 0) {
ctx.succeed('Yay');
// we add the callback here to make it testable
// we'll show in the next step how we make this DRY
if (cb) cb();
} else {
ctx.fail('Nay')
if(cb) cb('Error');
}
}
We would write this unit test:
'use strict';
const expect = require('chai').expect
, SomeLambda = require('./some-lambda-func')
, MockContext = require('./mock-lambda-context');
describe('Some Lambda Func', function() {
let ctx;
before(function() {
ctx = new MockContext();
});
describe('When Some param is greater than zero', function() {
before(function(done) {
SomeLambda({someParam: 10}, ctx, done)
});
it('should succeed with Yay', function() {
expect(ctx.succeed.calledWith('Yay')).to.equal(true)
});
after(function() {
//reset counters
ctx.reset();
})
})
});
Lets break it down:
- We defined our Lambda function. It will receive 3 parameters: an input object (e), a context object (ctx) and an optional callback (cb). We discussed the input and the context objects above, the callback is needed in this example so we can signal to Mocha that our function finished running. Since our Lambda returns it’s output asynchronously using the context object, the test would timeout without it. In the next step we will show a cleaner solution to this problem.
- We defined our unit test. We prepared our context object, called our function with an input of {someParam: 10} and made an assertion that it called the context object’s succeed function with a certain input.
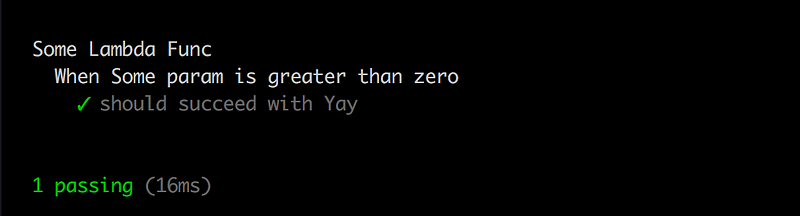
When we run it with “mocha some-lambda-func.spec.js”, we get:
ES6 Generators
In addition, we wanted to write our lambda function as an ES6 generator function, so we could use yield statements to write cleaner and readable code. Since the Lambda service expects a very specific signature from our functions, we decided to write a “factory function” which would translate our super-hip generator functions into something Lambda could digest easily. Ideally, using it would allow us to write Lambda functions that look like this:
'use strict';
const LambdaRunner = require('co-lambda-runner')
, DB = require('./db');
function *main(e) {
let id = e.params.id;
return yield DB.get(id);
}
module.exports = LambdaRunner(main);
We wanted this factory function to have this behaviour:
- Expose an interface like function(e, ctx) {}, which is required by Lambda.
- Try to run the generator function using co(), if everything went well, pass the returned value to ctx.succeed(), if an error is thrown send the error to ctx.fail()
- In case of an error, do some juggling with the error message which is needed by API Gateway to know what HTTP status code to return. (More on this in the third part of this article).
- Accept a callback parameter and call it, as is required to make the function easily testable using Mocha.
We ended up with something like this:
'use strict';
const co = require('co');
module.exports = function(lambda) {
return function(e, ctx, cb) {
co(
function* () {
let result = yield lambda(e, ctx);
if (cb) {
cb(null, result)
}
ctx.succeed(result);
}
)
.catch(
function(err){
let re = /Not found:/, msg;
if( err && re.test(err)) {
msg = err.message || err || "Not found: could not find resource";
} else {
msg = `Error: ${err.message || 'Internal error'}`
}
ctx.fail(msg);
if(cb) {
cb(err)
}
}
);
}
};
Wrapping Up
In this part of the article, we reviewed why we chose to deploy a microservice using serverless architecture, how we mock the Lambda context object to make it testable and how we create an interface between Lambda and super-hip ES6 generator functions. In the next two parts we will see how we:
- Deploy our code to Lambda using a tool called apex
- Programmatically manage our API Gateway using Swagger files and the AWS API
See you soon!